Architecture
Gonka 的推理流程
下面的图表和描述概述了推理请求如何在 Gonka 网络中传输,这是一个旨在平衡性能与加密保证的去中心化网络。 Gonka 只记录用于推理验证的交易和工件。实际计算在链下进行。
推理请求在独立的主机(所有网络参与者,而非中央调度器)之间移动。系统是去中心化的,没有单一节点将推理请求定向到网络节点。实际上,每个主机至少部署两个节点:
- 网络节点处理通信,包括:
- 连接到区块链的链节点
- 管理用户请求的 API 节点
- 一个或多个 ML 节点(推理),执行 LLM 推理(ML 节点可以部署在多台服务器上)。
下面的图表显示了推理请求通过 Gonka 网络的流程。绿色箭头表示通过公共互联网的通信,黄色箭头表示主机私有网络内的通信。
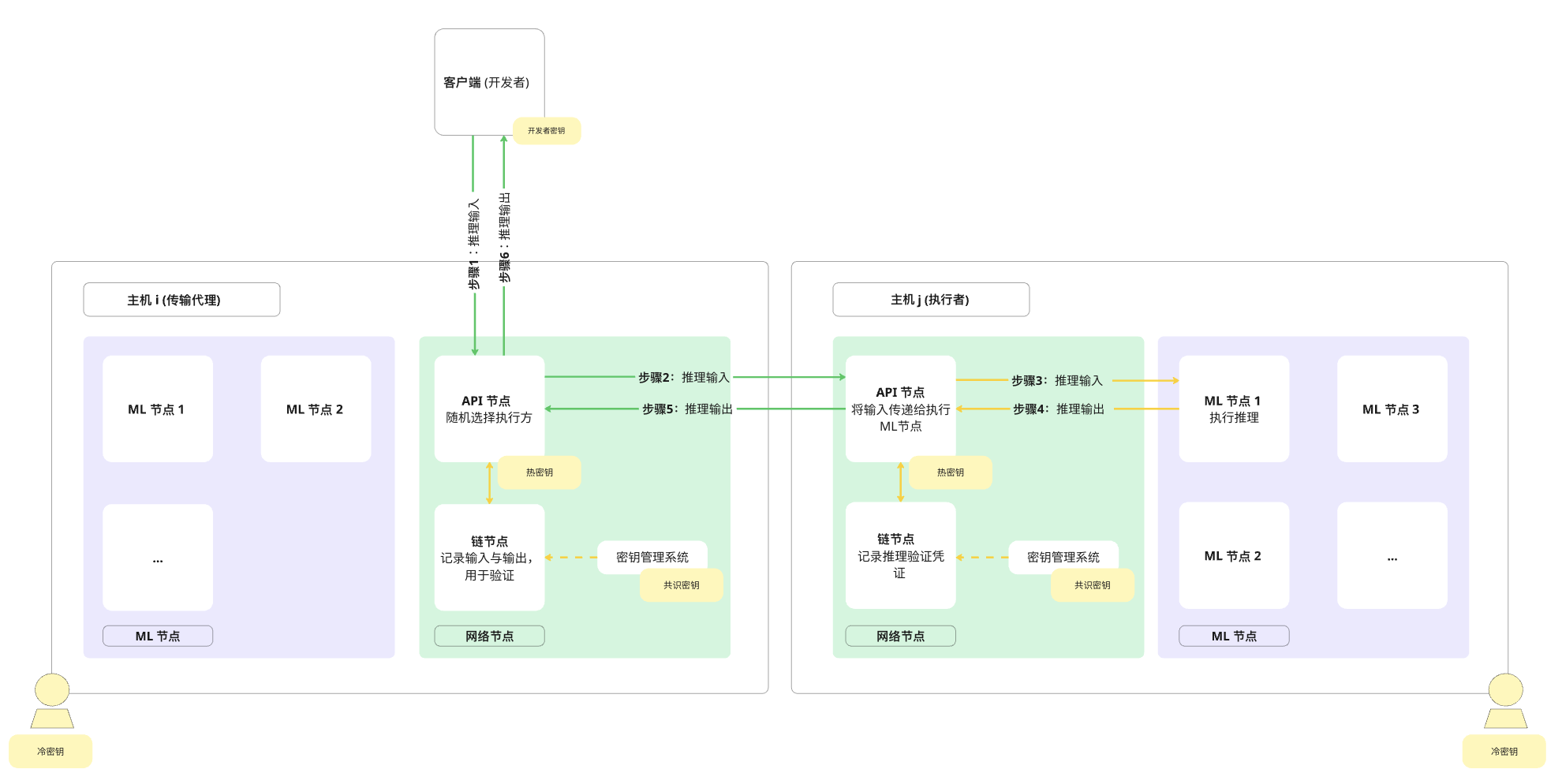
以下序列描述了推理请求如何通过 Gonka 网络移动,如上图所示:
- 步骤 1. 客户端(开发者)从活跃参与者(主机)列表中随机选择一个节点。这个随机主机充当传输代理(TA),并将推理请求发送到其 API 节点。任何主机都可以充当验证者、TA 和执行者(这些不是预定义或链上角色,而是在处理请求时承担的动态操作功能)。
- 步骤 2. TA 在所有其他活跃主机中随机选择一个执行者,并将推理输入传递给执行者的 API 节点。同时,TA 的链节点在链上记录推理输入。请注意,链上记录不会阻碍 LLM 计算,并且与执行者完成的工作并行进行。
- 步骤 3. 执行者的 API 节点将请求转发到其 ML 节点之一,该节点立即开始运行推理。
- 步骤 4. 计算完成后,执行者的 ML 节点将推理输出返回到执行者的 API 节点。
- 步骤 5. 执行者的 API 节点将输出发送回 TA 的 API 节点,同时执行者的链节点在链上记录验证工件。
- 步骤 6. TA 的 API 节点将输出返回给客户端(开发者),同时 TA 的链节点在链上记录它。请注意,虽然这些链上条目会占用整体网络带宽,但它们不会为特定的推理计算增加开销。
性能与验证
区块链记录既不会减慢推理计算开始的时间,也不会减慢最终结果可供客户端使用的时间。验证推理是否诚实执行是在之后进行的,与其他推理并行。如果发现执行者作弊,他们将失去整个周期的奖励,客户端将收到通知并获得退款。 请注意,该图表显示了高级别的推理流程,并未显示网络的完整复杂性。例如,它没有显示主机链节点之间的直接通信,也没有包括桥接或几个其他在此抽象级别不相关的内部组件。
计算证明(PoC)时间线
计算证明是一种新颖的共识机制,它保留了传统工作量证明的所有优势,即权重、工作负载和奖励与计算能力对齐(与权益证明不同,权益证明将权重与质押的代币对齐)。与工作量证明不同,计算证明将证明部分(Sprint)集中在短时间窗口内,释放其余时间用于有用的工作(在我们的案例中是 LLM 推理)。 Gonka 以周期(epoch)运行,每个周期持续 17280 个区块(约 24 小时)。
每个周期遵循严格的序列,将 Sprint 执行、主机活动和奖励结算绑定到一个连贯的流程中。
每个 Sprint 同时为所有主机开始,通过消除任何基于时间的优势来确保公平性(就像比赛中的发令枪,任何主机都不能提前开始)。这个同步开始是使用无法提前预测或影响的随机种子来协调的。所有具有投票权的主机都参与生成这个种子,防止任何少数主机集预先计算或获得不公平的优势。
Sprint 被故意设计得很短,将计算工作集中在紧密且有界的有效窗口内。它们以与区块链区块生产对齐的规律、精确定义的间隔发生,只占用总周期长度的一小部分。通过设计,Sprint 持续时间被最小化,以便周期的大部分时间可用于有意义的工作,例如 LLM 推理和训练。这种可预测的节奏允许 Sprint 执行自然地集成到去中心化 AI 网络的整体运营中,而不会干扰生产性工作负载。

一个周期以自动申领周期 N 的奖励结束。新的计算证明阶段(Sprint)开始确定即将到来的周期的主机权重。一旦 Sprint 完成并分配了权重,这标志着新周期的开始。
在整个周期中,主机运行并验证推理。
如果由于某种原因周期 N 的奖励未被申领,每个主机的 API 节点会在周期 N+1 中自动提交周期 N 的奖励申领交易,使用在周期 N 开始时签名的种子。申领每 30 分钟重试一次,直到成功。重要的是,主机必须保持在线并在此有限窗口内通过所有验证检查,否则链无法完成申领,奖励将保持未申领状态。来自较早周期(周期 N)的未申领奖励一旦周期 N+2 开始就会被永久销毁。
作为申领过程的一部分,链会验证主机是否完成了周期所需的所有工作。协议还允许在此窗口期间提交逾期的推理验证工件,为主机提供在奖励最终确定之前执行任何待处理验证的最后机会。