Architecture
Inference flow across Gonka
The diagram and description below outline how inference requests travel through Gonka, a decentralized network designed to balance performance with cryptographic guarantees. Gonka only records transactions and artifacts for inference validation. The actual computation happens off-chain.
Inference requests move across independent Hosts (all network participants, not a central scheduler). The system is decentralized, with no single point directing inference requests to the network nodes. In practice, each Host deploys at least two nodes:
- Network Node handles communication and consists of:
- a Chain Node that connects to the blockchain
- an API Node that manages user requests
- One or more ML Nodes (inference) which perform LLM inferences (ML Nodes could be deployed across multiple servers).
The diagram below shows the flow of an inference request through the Gonka network. Green arrows indicate communication over the public internet, while yellow arrows indicate communication within a Host’s private network.
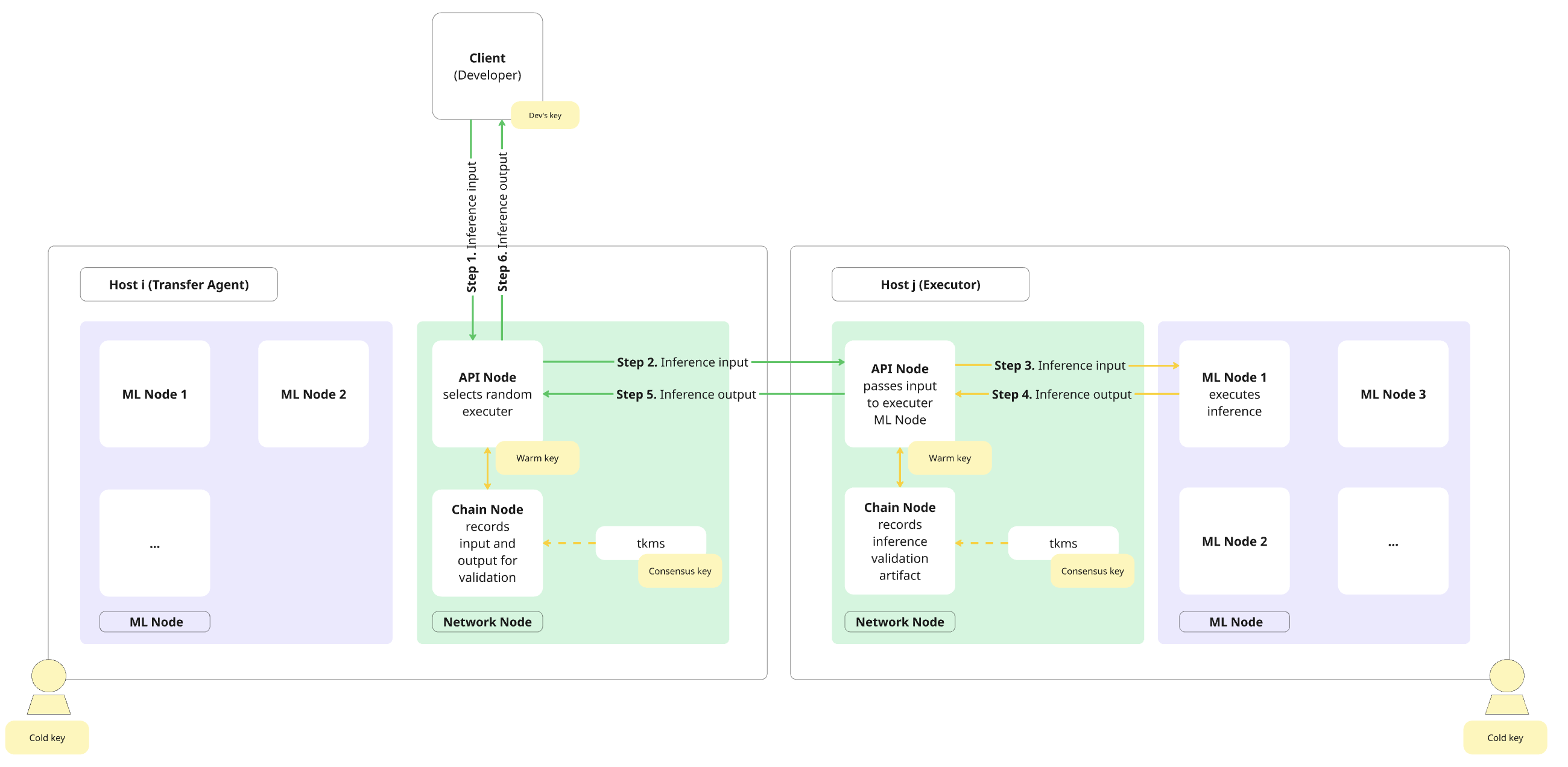
The following sequence describes how an inference request moves through the Gonka network as illustrated in the diagram above:
- Step 1. A Client (Developer) selects a random node from the list of active participants (Hosts). This random Host acts as the Transfer Agent (TA) and gets an inference request to its API node. Any Host acts as Validator, TA and an Executor (these are not predefined or on-chain roles, but dynamic operational functions assumed when processing a request).
- Step 2. The TA randomly selects an Executor among all other active Hosts and passes the inference input to the Executor’s API node. In the meantime, the TA’s Chain Node records inference input on-chain. Note that the on-chain record does not hold back the LLM computation and is made in parallel with the work done by the Executor.
- Step 3. The Executor’s API node forwards the request to one of its ML Nodes, which begins running inference immediately.
- Step 4. Once computation is complete, the Executor’s ML Node returns the inference output to the Executor’s API node.
- Step 5. The Executor’s API node sends the output back to the TA’s API node, while the Executor’s Chain Node records a validation artifact on-chain.
- Step 6. The TA’s API node returns the output to the Client (Developer), while the TA’s Chain Node records it on-chain. Note that while these on-chain entries contribute to overall network bandwidth constraints, they don’t add overhead to a particular inference computation.
Performance & Validation
Blockchain records are not slowing down either the moment when inference computation starts, nor the moment when final results are available to the client. The validation that inference was done honestly happens afterwards, in parallel with other inferences. If an Executor is caught cheating, they’ll lose rewards for the whole epoch, and the client will be notified and get their money back. Note that the diagram shows inference flow on a high-level and does not show full complexity of the network. For example, it does not show direct communication between Hosts’ Chain Nodes, and does not include the bridge or several other internal components not relevant at this abstraction level.
Proof of Compute (PoC) timeline
Proof or Compute is a novel consensus mechanism which retains all the benefits of traditional Proof of Work in terms of aligning weight, workload and rewards with computational power (unlike Proof of Stake which aligns weight with the staked coins). Unlike Proof of Work, Proof of Compute concentrates the proving part (Sprint) in a short limited time window, freeing the rest of the time for the useful work (in our case LLM inference). Gonka operates in epochs, each epoch lasts 17280 blocks (approximately 24 hours).
Each epoch follows a strict sequence that ties Sprint execution, Hosts activity, and reward settlement into a cohesive flow.
Each Sprint begins simultaneously for all Hosts, ensuring fairness by eliminating any advantage based on timing (much like a starting gun in a race, where no Host may begin early). This synchronous start is coordinated using a random seed that cannot be predicted or influenced beforehand. All Hosts with voting power contribute to generating this seed, preventing any minority set of Hosts from pre-computing or gaining an unfair edge.
Sprints are deliberately short, concentrating computational effort into a tightly bounded and efficient window. They occur at regular, precisely defined intervals aligned with blockchain block production, taking only a small fraction of the total epoch length. By design, Spring duration is minimized so that the majority of epoch remains available for meaningful work, such as LLM inference and training. This predictable rhythm allows Sprint execution to integrate naturally into the overall operation of the decentralized AI network without interfering with productive workloads.

An epoch concludes with auto claiming rewards for epoch N. The new Proof of Compute phase (Sprint) begins to determine Hosts weights for the upcoming Epoch. Once Sprint is completed and weights are assigned, this marks the start of the new epoch.
Throughout the epoch, Hosts run and validate inferences.
If for some reason a reward for epoch N was not claimed, each Host’s API node automatically submits a reward claim transaction in epoch N+1 for epoch N using the seed that was signed at the start of epoch N. The claim is retried every 30 minutes until it succeeds. Importantly, the Host must remain online and pass all verification checks within this limited window, otherwise, the chain cannot finalize the claim, and the reward remains unclaimed. Unclaimed rewards from earlier epochs (epoch N) are permanently burned as soon as epoch N+2 begins.
As part of the claim process, the chain verifies that Host completed all required work for the epoch. The protocol also allows overdue inference-validation artifacts to be submitted during this window, giving Hosts a final opportunity to execute any pending validations before rewards are finalized.